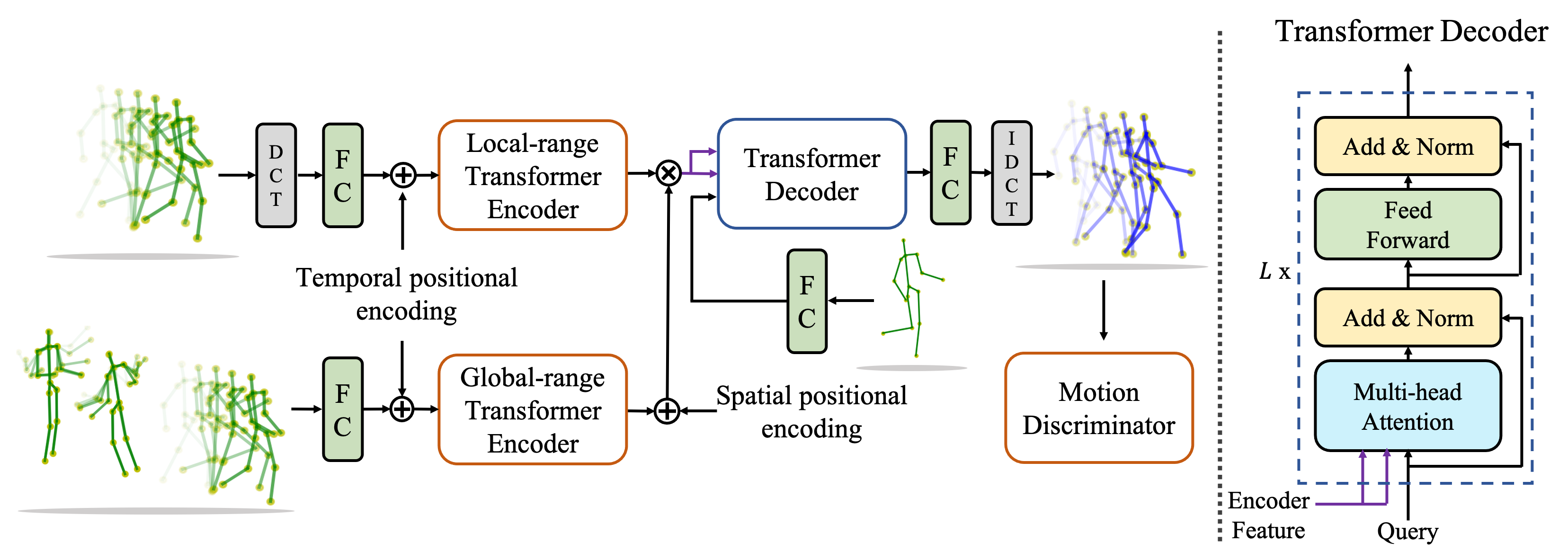
We propose a novel framework for multi-person 3D motion trajectory prediction. Our key observation is that a human's action and behaviors may highly depend on the other persons around. Thus, instead of predicting each human pose trajectory in isolation, we introduce a Multi-Range Transformers model which contains of a local-range encoder for individual motion and a global-range encoder for social interactions. The Transformer decoder then performs prediction for each person by taking a corresponding pose as a query which attends to both local and global-range encoder features. Our model not only outperforms state-of-the-art methods on long-term 3D motion prediction, but also generates diverse social interactions. More interestingly, our model can even predict 15-person motion simultaneously by automatically dividing the persons into different interaction groups.
We show the results of our method. Green color represents the input and blue represents the output. The results show that our method can predict smooth and natural multi-person 3d motions.
We show our method compared with the other methods. Green color represents the input and blue represents the output. Our results are not only the closest to the real records but also very smooth and natural. It can be seen that RNN-based method (SocialPool) will quickly produce freezing motion. When predicting the absolute skeleton joint positions, decoding based on an input seed sequence (HRI) or adding the input sequential residual to the output (LTD), will make the predicted motion have hysteresis and repeat the history.